An Overview Of Three Text-to-SQL Models And Methods
Author: Xing Voong, posted on 03-22-2024
I choose to explain and review 3 text-to-SQL models and methods. They are DAIL-SQL, RAT-SQL, and SQLNet.
Before going into details of the above three methods. I want to introduce a base architecture for many text-to-SQL systems. Knowing this architecture would make understanding other text-to-SQL systems easier.
Table of Content
II: Benchmark
III: Limitations and Opportunities for
Improvement
IV: A Proposal For Improvements
V: Summary
VI: Acknowledgement
I: Explain and Review
1: DAIL-SQL
DAIL-SQL is an method that uses supervised fine-tuning text-to-SQL and prompt engineering empowered by large language models (LLMs).
Supervised fine-tuning text-to-SQL
The current best result for this approach yields from fine-tuning GPT4 on Spider Dev dataset 1, a popular dataset for text-to-SQL tasks.
Prompt Engineering
This is where text-to-SQL approaches that are empowered by LLMs get interesting. In this method, prompt engineering divides the work into 2 sub-tasks: question-representation and in-context-learning.
A: Question representation
How to instruct LLMs is important. According to the Text-to-SQL Empowered by Large Language Models: A Benchmark Evaluation paper 2 published in Aug 2023, in which DAIL-SQL was introduced, here is a good prompt to give LLMs, especially gpt4.
### Complete sqlite SQL query only and with no explanation
### SQLite SQL tables , with their properties
#
# continents ( ContId , Continent )
# countries ( CountryId , CountryName , Continent )
#
### How many continents are there ?
SELECT
Below can be a general form of instruction:
Given:
{table_info}
Task:
provide the sqlte SQL query for this question:
Question:{input}
Answer Query: ""
With only given question and no given answer, this is also called zero-shot learning.
B: In-context-learning
Given proper instruction is good but teaching LLMs step by step on how to answer a question is better. By providing a question with SQL schemas, logic to the answer, and the answer, fine-tuned text-to-SQL LLMs perform better.
A learning example contains 3 parts. Part 1 is a prompt that has SQL tables and a SQL question. Part 2 is the logic to get to an answer. Part 3 is the answer.
Example:
Part 1: SQL tables and a SQL question
/* Given the following database schema : */
CREATE TABLE IF NOT EXISTS " gymnast " (
" Gymnast_ID " int ,
" Floor_Exercise_Points " real ,
" Pommel_Horse_Points " real ,
" Rings_Points " real ,
" Vault_Points " real ,
" Parallel_Bars_Points " real ,
" Horizontal_Bar_Points " real ,
" Total_Points " real ,
PRIMARY KEY ( " Gymnast_ID " ) ,
FOREIGN KEY ( " Gymnast_ID " ) REFERENCES " people " ( " People_ID " )
) ;
CREATE TABLE IF NOT EXISTS " people " (
" People_ID " int ,
" Name " text ,
" Age " real ,
" Height " real ,
" Hometown " text ,
PRIMARY KEY ( " People_ID " )
) ;
/* Answer the following : Return the total points of the gymnast with the lowest age . */
Part 2: the logic to get to an answer
- The question asks for the gymnast’s point which can be found in the gymnast table.
select gymnast_id, total_points from gymnast- Then it asks for the lowest age which is in the people table but need to order by age and limit to one choice.
select people_id, age from people_table order by age asc limit 1- gymnast table and people table link through gymnast_ID and people_ID which mean you need to use join on gymnast_id and people_id
select t1.total_points from gymnast as t1 join people as t2 on t1.gymnast_id = t2.people_id
Part 3: The Answer
Based on the above logic, the answer is:
select t1.total_points from gymnast as t1
join people as t2 on t1.gymnast_id = t2.people_id
order by t2.age asc limit 1
According to the paper, the best result yielded from giving five examples of combinations: a question - logics to the answer and the answer. With one example combination, it is one-shot learning. With five example combinations, it is 5-shot-learning. Figure 2 is an in-depth diagram summarized DAIL-SQL 3
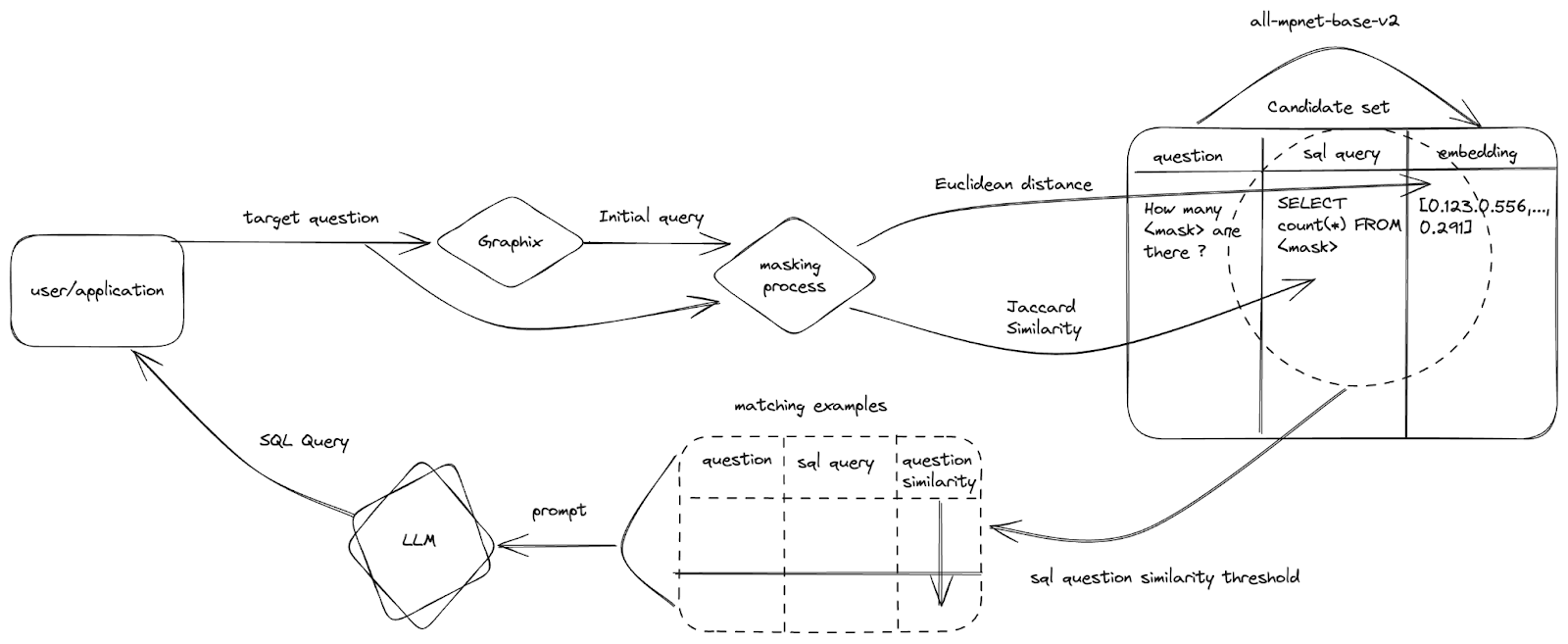
Notice that by using Figure 1 as a baseline system, we can produce Figure 2 by adding needed mechanisms.
2: RAT-SQL
One challenge of text-to-SQL tasks is to generalize unseen database schemas. The paper RAT-SQL: Relation-Aware Schema Encoding and Linking for Text-to-SQL Parsers 4 published on 10 Nov 2019, introduces a method called RAT-SQL to address this problem by schema encoding and schema linking.
After converting SQL schemas to graph schemas, the Relation Aware (hence the name RA) encoder also uses the self-attention mechanism to encode data schemas. The schema linking layer outputs tree structures for a decoder to generate SQL result queries.
For schema linking, there are three services.
- Name-based linking links information in a question to match SQL columns and tables names in the database.
- Value-based linking links information in a question to match SQL columns and tables values in the database.
- Alignment linking links information in a question that aligns with SQL columns and tables in the database.
3: SQLNet
SQLNet is a text-to-SQL method that was introduced in SQLNet: Generating Structured Queries From Natural Language Without Reinforcement Learning 5 paper published on 13 Nov 2017. SQLNet avoids serialize SQL queries, then decode with reinforment learning, because it is hard to improve reinforment learning. SQLNet uses main three mechanisms which are sketch-based, sequence-to-set and column attention to improve the performance of text-to-SQL task.
-
Sketch-based
- A sketch is a dependency graph which present the syntactical structure of a SQL query. A sketch generates and makes SQL queries predictions based on the previous prediction.
-
Sequence-to-set
- Predicting which column names in a subset of interests instead of generating a sequence of column names.
-
Column Attention
- is a instance of the generic attention mechanism that using column names to compute feature map on a question.
II: Benchmark
The dataset for benchmarking is Spider Dataset.
| Execution Accuracy | GPU Hours | Hardware Used | |
|---|---|---|---|
| DAIL-SQL | 86.6% | 54.4 hours | a server with eight 64G A100 GPUs |
| RAT-SQL | 57.2% | 7 days | V100 GPU card |
| SQLNet | 12.4% | unknown * | unknown * |
*There are no reported GPU hours and hardware used for SQLNet on Spider dataset. It is not on the published paper and Spider dataset leaderboard
III: Limitations and Opportunities for Improvement
Limitations
In general, all three methods can generalize unseen schemas. They also do not expose the underline datasets. However, all three models are vulnerable to attacks. Users can input suspicious strings (e.g. strings that contain code). In that case, the output SQL queries could be malicious. Users can also form questions that produce unreversed queries such as DROP which would cause damage to databases.
On top of that, each method has its shortcomings.
- DAIL-SQL
- privacy could be a concern. prompts need to be carefully crafted so that they do not expose datasets.
- Fine-tuning LLMs is expensive.
- Prompt engineering is a new field of art and science. It is hard to hire experts for the tasks.
- RAT-SQL
- with schema linking, it is hard to fine-tune.
- with encode-decode from one format to another, information and structural relationships between schemas can be lost.
- The accuracy is not great. With 57.2%, the result queries could be wrong nearly half of the time.
- SQLNet: one of the first models that shed light on text-to-SQL tasks but it has not been up to date on use cases in production.
Improvement
Some traditional software engineering implementations could cover ML/AI shortcomings such as:
- maintaining regular backups for databases
- denying all unreversed SQL words like DROP, TRUNCATE, RESET MASTER, and DELETE.
IV: A Proposal For Improvements
I chose to take inspiration from DAIL-SQL and improve on this method.
Even though close-source LLMs from OpenAI such as Gpt3 Turbo and Gpt4 give state-of-art results, they are expensive to use in the long run. I chose to replace them with open-source LLMs, one example would be Llama-2 from Meta.
On the other hand, there is a new dataset BIRD-SQL, A Big Bench for Large-Scale Database Grounded Text-to-SQLs 6 which is a more realistic dataset than Spider Dataset.
Prompt engineering can also be improved. Instead of just giving random prompts. Engineers can give prompts that cover some essential SQL use cases. Here is a list of them.
1. SELECT column
2. AGGREGATION: None, COUNT, SUM, AVG, MIN, MAX
3. Number of WHERE conditions: 0, 1, 2, 3
4. WHERE on column
5. WHERE OPERATORS: =, <, >
6. WHERE on a VALUE
Putting the above reasons together, the flow of a proposal approach could be:
- Pick an open-source LLM, let’s say Llama-2.
- fine-tuning this model with Spider Dataset.
- random prompt engineering with this fine-tuned dataset for evaluation.
- train the model again on the BIRD dataset.
- prompt engineering of the newly trained model with essential SQL use cases for usage.
V: Summary
I started by introducing a base architecture for text-to-SQL systems. I then explained and reviewed three approaches for text-to-SQL tasks. They are DAIL-SQL, RAT-SQL and SQLNet. I included their benchmark, limitations, and room for improvement. I ended with an outline for an approach that could be used in real-world applications.
VI: Acknowledgement
This has been a challenging yet fun project. Along with the footnotes, the project is made possible due to the resources I read from:
- On the Vulnerabilities of Text-to-SQL Models by Xutan Peng, Yipeng Zhang, Jingfeng Yang, Mark Stevenson
- Text-to-SQL Benchmarks and the Current State-of-the-Art by Ainesh Pandey
- Five parts of Text2SQL blog on Medium by Devshree Patel
- We Fine-Tuned GPT-4 to Beat the Industry Standard for Text2SQL by Michael Fagundo and Clemens Viernickel on https://scale.com/blog
- Generating value from enterprise data: Best practices for Text2SQL and generative AI by Nitin Eusebius, Arghya Banerjee, and Randy DeFauw on AWS Machine Learning Blog
- [Text-to-SQL] Learning to Query Tables with Natural Language by Ms Aerin
- A Comprehensive Guidance of Prompt Engineering for Natural Language to SQL by Chelse Ma
- hasura.io